
After completing a successful takeoff, an onboard camera attached to Arizona Autonomous' Trex-700N comes to life and begins taking a deep look at the environment around it in an attempt to find very specific features. Teaching yourself how to recognize something probably takes just a few seconds but teaching a computer how to find features in an image is a very difficult process. Let's take a look at how AZA's computer vision algorithms work.
| Once an image is captured by the camera, a series of transformations are completed on the image to find the given target. Pictured on the right is an overview of the specific process that was used to determine target validity, shape, color, embedded alphanumeric color, alphanumeric letter, and alphanumeric orientation. | 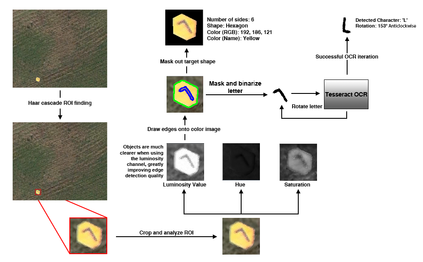 |
The first process is completed in real-time using a Haar feature cascade classifier, which is a region of interest (ROI) detection algorithm that searches for objects of visual interest in an image. If an object is found, the image is then cropped to the detected ROI and passed into further modifiers. Several different channels are then extracted from the image including the Hue-Saturation-Value (HSV) and luminosity. The luminosity channel is then processed using the Canny edge detection algorithm which finds "strong edges" within the image and identifying connecting edges. A custom algorithm was created to combine edges based on their relative distance, reducing the fragmented edges to a larger outline and a smaller embedded alphanumeric outline.
Next, several different algorithms are run in parallel to further analyze the image and begin to identify its features. The target outline is approximated to a polygon using the Douglas-Peucker algorithm and the number of edges is compared to a table of polygon edge counts and names. The RGB values of the masked image are averaged in order to determine the target’s average RGB color. The resulting color tuple is compared to a table of common colors, and the closest match within acceptable error range is used to label the target.
To determine letter orientation, alphanumeric color, and alphanumeric character the outline generated for the embedded character is then processed. Optical Character Recognition (OCR) is used to determine the alphanumeric character embedded in the target using Tesseract. To enhance compatibility with Tesseract's algorithms, the extracted character outline is filled and redrawn on a blank background, yielding a binary image.The character is then deskewed using plausible character orientations or by rotating the image by 10 degrees at a time until a letter is recognized. Upon successful character recognition, the degree rotation and image metadata are used to determine the alphanumeric cardinal orientation.
If you were to look at that image it would be fairly easy to determine that the image contained a yellow hexagon with a black L inside, but teaching a computer to know that requires a much finer approach. In the 2016-17 academic year, AZA will be developing a new method of executing its computer vision tasks which is currently in development.
Next, several different algorithms are run in parallel to further analyze the image and begin to identify its features. The target outline is approximated to a polygon using the Douglas-Peucker algorithm and the number of edges is compared to a table of polygon edge counts and names. The RGB values of the masked image are averaged in order to determine the target’s average RGB color. The resulting color tuple is compared to a table of common colors, and the closest match within acceptable error range is used to label the target.
To determine letter orientation, alphanumeric color, and alphanumeric character the outline generated for the embedded character is then processed. Optical Character Recognition (OCR) is used to determine the alphanumeric character embedded in the target using Tesseract. To enhance compatibility with Tesseract's algorithms, the extracted character outline is filled and redrawn on a blank background, yielding a binary image.The character is then deskewed using plausible character orientations or by rotating the image by 10 degrees at a time until a letter is recognized. Upon successful character recognition, the degree rotation and image metadata are used to determine the alphanumeric cardinal orientation.
If you were to look at that image it would be fairly easy to determine that the image contained a yellow hexagon with a black L inside, but teaching a computer to know that requires a much finer approach. In the 2016-17 academic year, AZA will be developing a new method of executing its computer vision tasks which is currently in development.

 RSS Feed
RSS Feed
